Follow the Money: What Apify's Best-Selling Scrapers Teach Us
Before building my first scraper on Apify, I wanted to understand the marketplace.
What makes a scraper successful?
What do people actually pay for?
What features matter?
Rather than guess, I did what any web scraping enthusiast would do 🤓: I scraped the Apify Store, analyzed the data, and built a dashboard to explore the findings.
Here's what I learned.
TL;DR: Only 10.5% of scrapers see real usage • Social media dominates but Google Maps wins • Successful authors build portfolios, not one-offs • New scrapers can win fast
Table of Contents
- The Approach
- Building the Dashboard
- The 10% Rule: Extreme Market Concentration
- Social Media Scrapers Own the Top Spots
- The Author Economics: Diversify or Dominate
- Age Is Just a Number: New Scrapers Can Win Fast
- What This Means for Scraper Builders
- What’s Next
The Approach
 Recording the HAR file while browsing the Apify Store in Firefox
Recording the HAR file while browsing the Apify Store in Firefox
I usually approach each web scraping session like this:
- Open a private browser window and developer tools
- Navigate to the pages where the data appears
- Save the HAR file (HTTP Archive) for the session
- Identify the request that fetches the data
- Implement a web scraper that reproduces this request
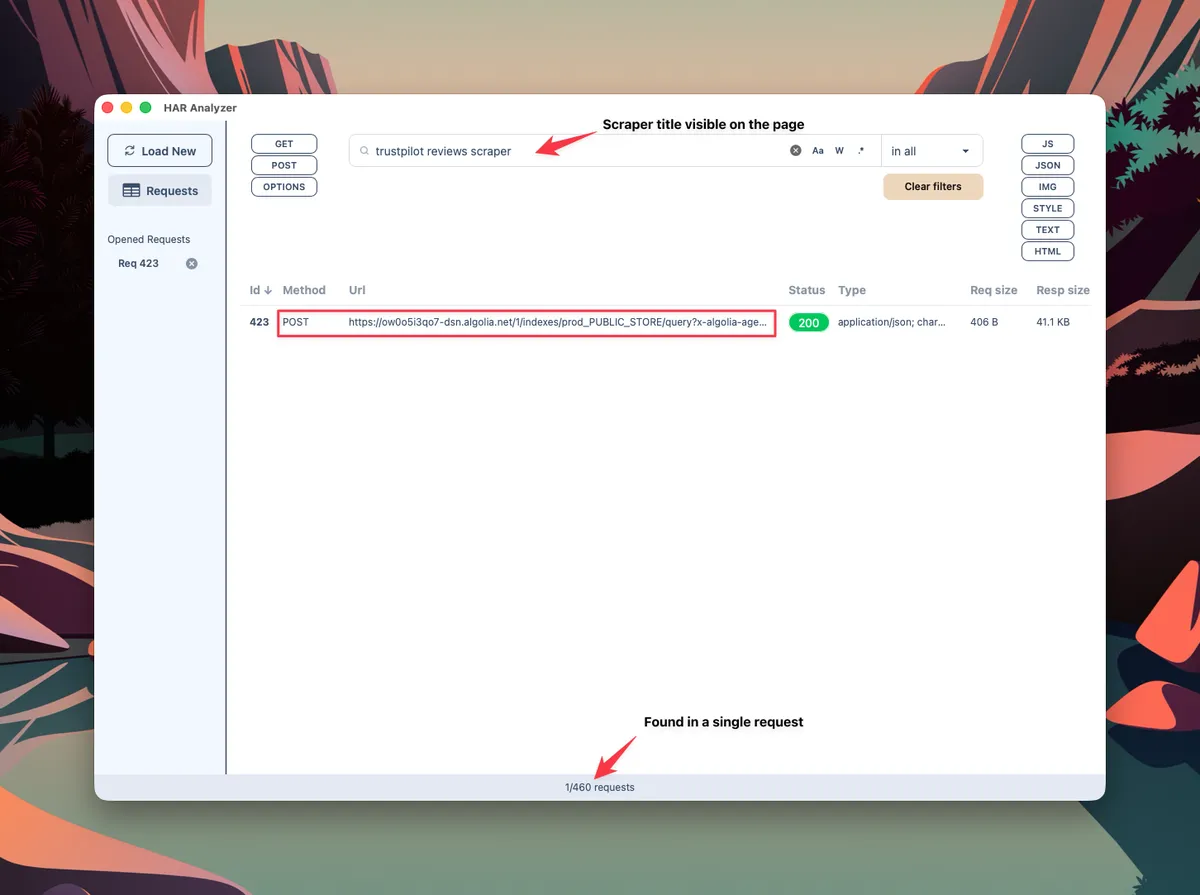 Searching for the request that lists Apify actors with my HAR Analyzer
Searching for the request that lists Apify actors with my HAR Analyzer
This turned out to be an Algolia request, which provided interesting insights about each listed scraper.
The stats field contained various metrics about builds, runs and users.
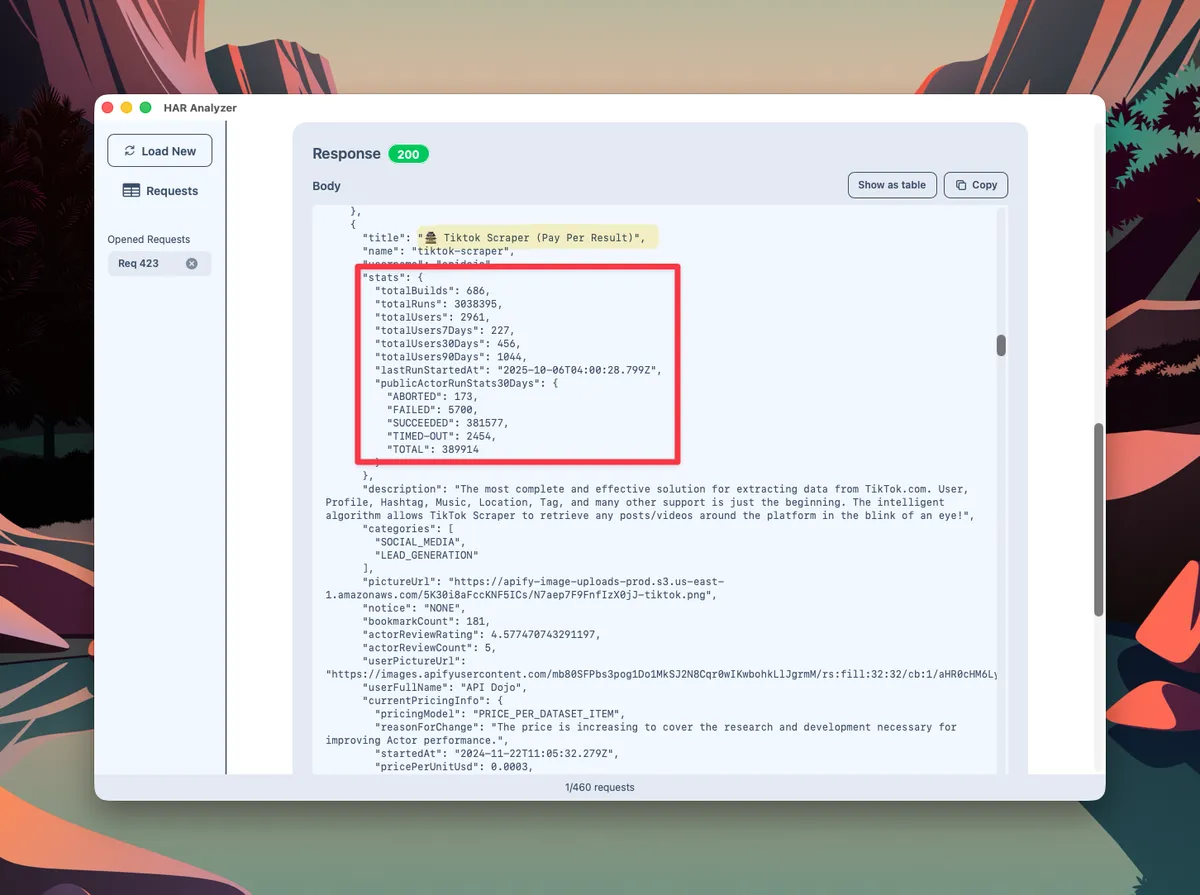 Extract of the response for the Algolia request listing Apify actors
Extract of the response for the Algolia request listing Apify actors
The Apify Store is essentially a paginated API returning JSON data for each actor. No complex anti-scraping measures, no dynamic JavaScript rendering—just straightforward HTTP requests.
The only optimization I made was tweaking the query parameters to reduce the number of requests, by increasing the number of results per page.
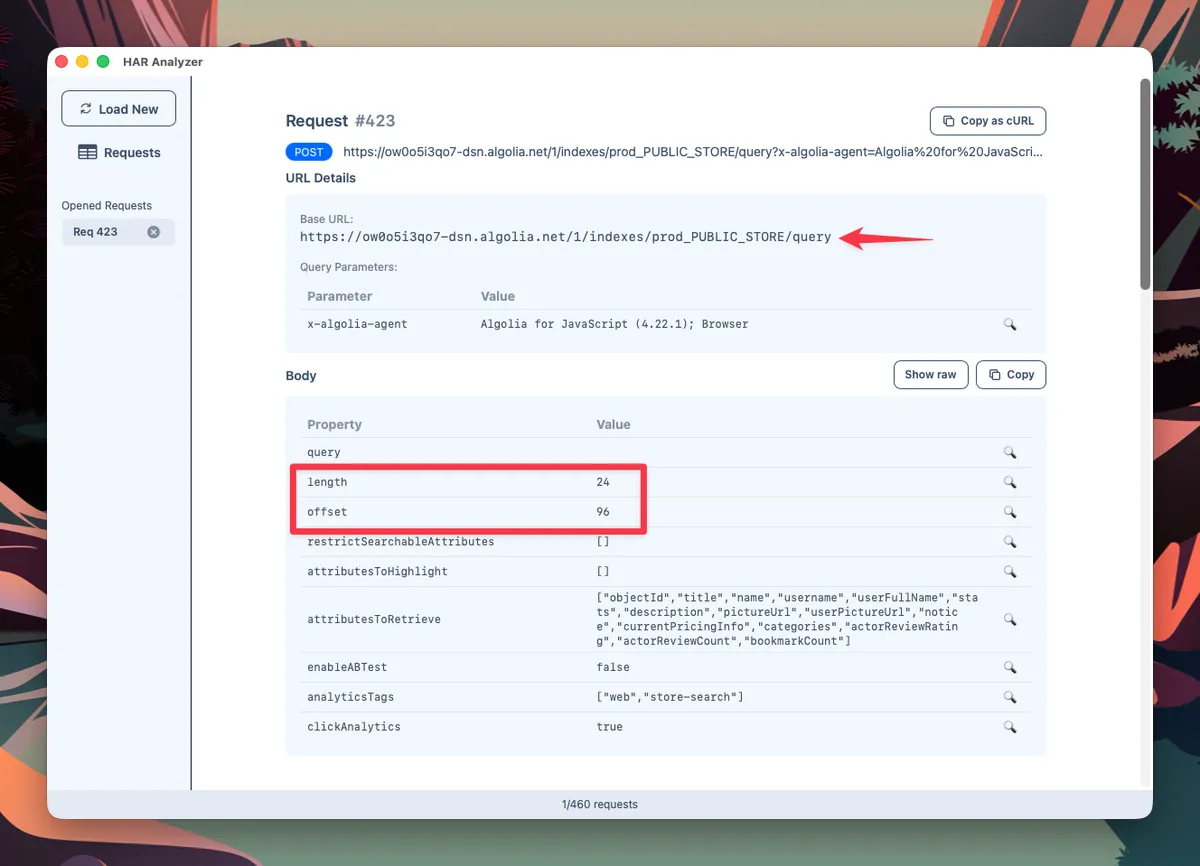 Highlighting the URL and original pagination parameters in the request
Highlighting the URL and original pagination parameters in the request
I collected data on:
- Pricing models and price points
- Run counts and user adoption
- Categories and target platforms
- Success rates
- Actor age and lifecycle data
- Author portfolios
Total dataset: 7525 actors across 17 categories.
Building the Dashboard
After collecting the data, I wanted an interactive way to explore it.
Spreadsheets weren’t cutting it—I needed visualizations and the ability to spot patterns quickly.
I used Claude Code to help me build a Streamlit dashboard.
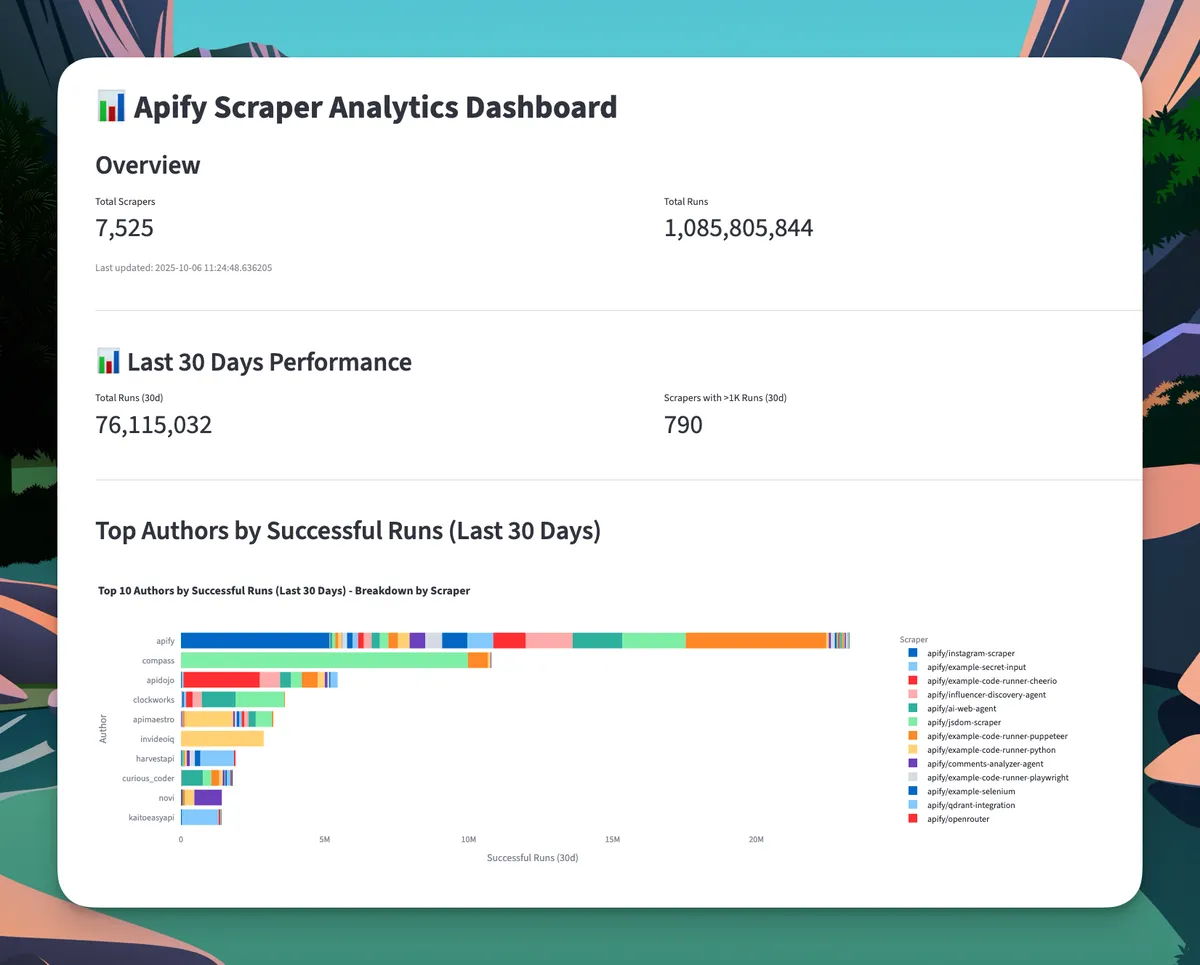 Overview of the Streamlit dashboard
Overview of the Streamlit dashboard
The system consists of three main components:
collector.py— fetches scraper data from Apify's Algolia API, merges paginated results, and stores both metadata and time-series metrics in a SQLite database.analyzer.py— queries this historical data with methods for calculating trends, aggregations, and insights like top performers and author rankings.dashboard.py— is a Streamlit app that visualizes everything through interactive charts showing real-time metrics, trends, and performance comparisons.
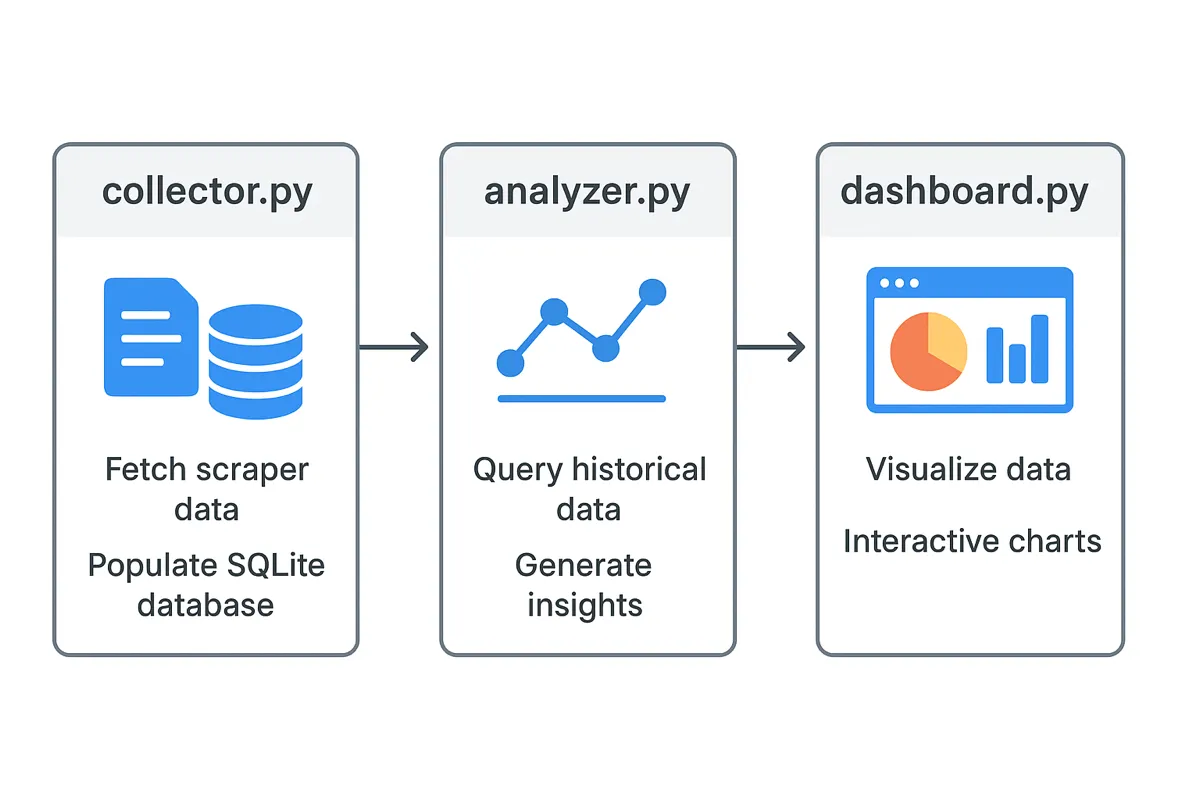 Dashboard architecture
Dashboard architecture
The 10% Rule: Extreme Market Concentration
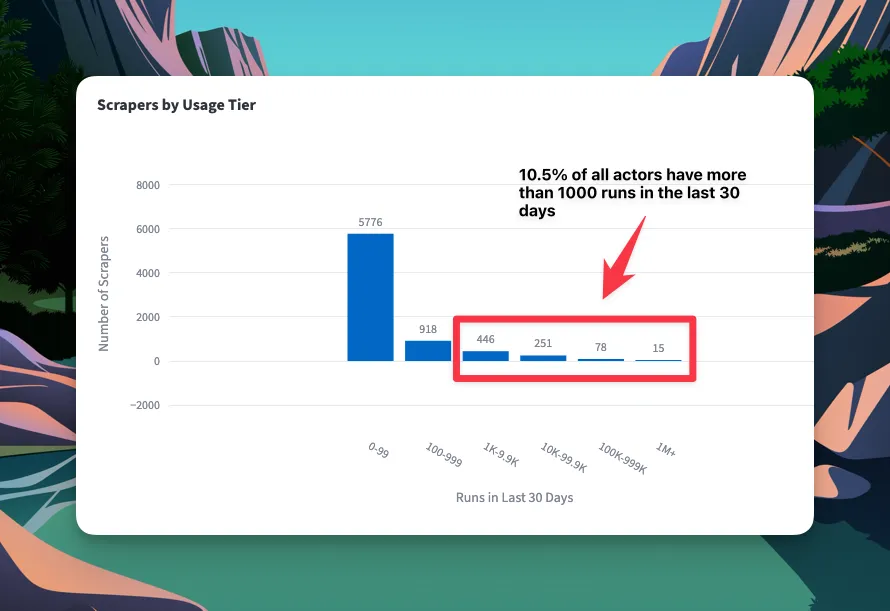 Chart showing distribution of runs in last 30 days
Chart showing distribution of runs in last 30 days
Only 790 scrapers (10.5% of all actors) have more than 1,000 runs in the last 30 days.
That means roughly 90% of scrapers on Apify are either abandoned experiments, niche tools for specific users, or projects that haven't found product-market fit.
The marketplace is winner-take-most, with a small fraction of actors driving the vast majority of activity.
It's a sobering reality check: building a scraper isn't enough. You need to solve a problem that many people have—or solve a niche problem extremely well.
Why this matters: If you're building an Apify actor, you're not just competing with 7,500 scrapers. You're competing with the top 800 that already solve real problems. Your scraper needs to be meaningfully better, cheaper, or target an underserved niche.
Social Media Scrapers Own the Top Spots
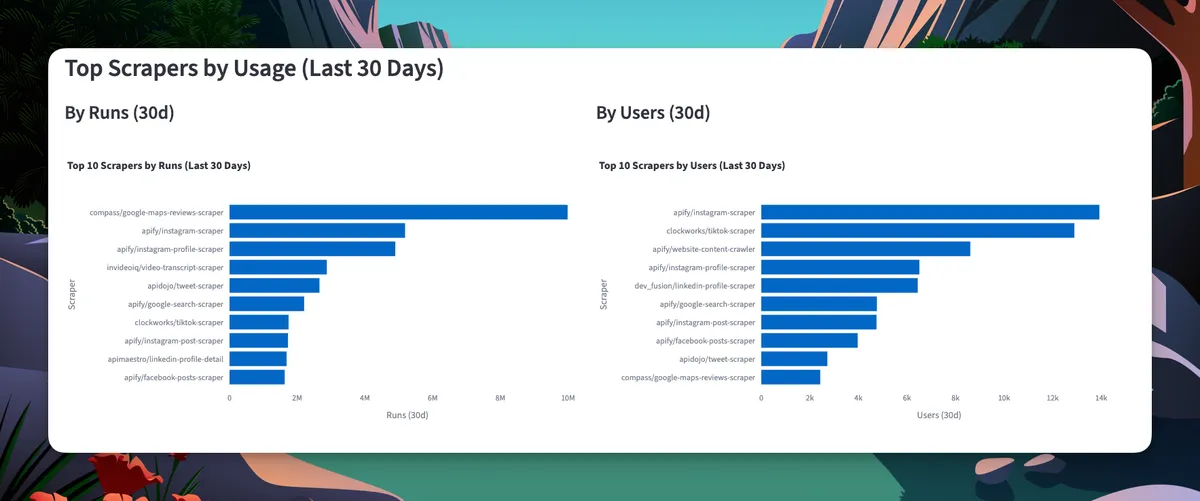 Top 10 Apify scrapers by runs and users over the past 30 days
Top 10 Apify scrapers by runs and users over the past 30 days
Instagram, Facebook, TikTok, and Twitter scrapers consistently dominate the rankings. These aren't just popular—they're in a different league.
But here's the surprise: the #1 scraper by volume isn't social media at all.
It's the Google Maps review scraper with almost 10 million runs in the past month—twice the volume of the runner-up scraper.
Why does a Maps scraper dominate? Because local business data is evergreen.
Marketing agencies monitoring client reviews, businesses tracking competitors, researchers analyzing sentiment, lead generation firms building contact lists—the use cases are endless and don't depend on chasing platform API changes like social media scrapers do.
Still, social media scrapers fill out the rest of the top 10. Instagram, Facebook, TikTok, and Twitter scrapers show both high user counts and high run volumes. These platforms change frequently, data access is restricted, and businesses have real, recurring needs for this data (competitor analysis, influencer research, content monitoring, lead generation).
Why this matters: Social media scrapers succeed because:
- High demand - businesses need this data constantly
- Moving targets - platforms change, so maintained scrapers have a moat
- Restricted APIs - official APIs are expensive or limited
- Recurring use cases - not one-time data pulls
The downside? These scrapers break often and require constant maintenance. You're signing up for an ongoing arms race with platform anti-scraping teams.
The Author Economics: Diversify or Dominate
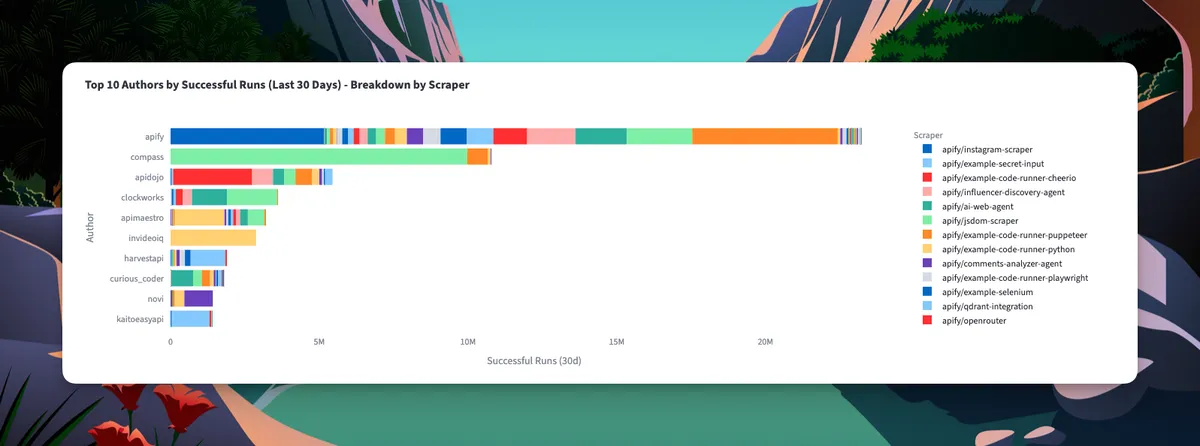 Top 10 authors by successful runs
Top 10 authors by successful runs
Apify holds massive market share, with their Instagram scraper alone driving enormous volume. But third-party authors have carved out substantial businesses:
Pro tip: Explore these scraper READMEs (like this one) to see best practices in documentation.
The data reveals an interesting pattern: successful authors rarely rely on a single scraper.
The color breakdown in the top 10 shows that most have diversified portfolios rather than one-hit wonders.
This makes sense.
Once you’ve built scraping infrastructure, proven reliability, and gained user trust, the marginal cost of launching additional scrapers drops significantly. You can reuse code, share monitoring systems, and cross-promote within your actor portfolio.
Why this matters: If you're serious about building on Apify, think in terms of a portfolio strategy, not a single bet.
Age is Just a Number: New Scrapers Can Win Fast
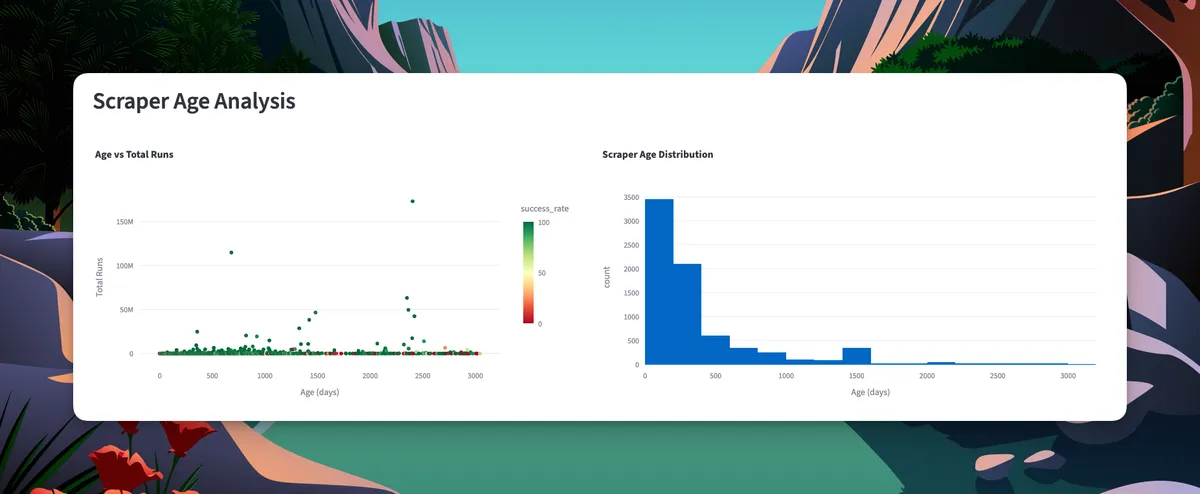 Actor age vs. total runs
Actor age vs. total runs
Most scrapers are relatively new (<500 days old), with only a handful of veterans operating for 2,000+ days.
Here's the interesting part: the scatter plot shows no clear correlation between age and total runs. New scrapers can achieve massive scale quickly.
That's encouraging. You don't need years of reputation to win. If you solve a real problem better than existing solutions, users will find you.
But there’s a caveat: while new scrapers can win fast, many older ones are still going strong.
Why this matters:
- Don't be intimidated by established scrapers—if you can build better, you can win
- Speed to market matters—identify gaps and move fast
- First-mover advantage exists but isn't insurmountable
- Focus on solving current problems, not what worked years ago
What This Means for Scraper Builders
Based on this analysis, here's what I'd focus on if I were building an Apify actor today:
1. Target the Top 10% or Find a Real Gap Don't build another generic scraper. Either significantly improve on what's in the top 790 or identify a category with demand but poor existing solutions.
2. Plan for Portfolio, Not a One-Off Successful authors build multiple related scrapers. Pick a niche (e-commerce, social media, real estate) and build 3-5 complementary actors.
3. Favor Evergreen Over Trendy The Google Maps scraper's dominance suggests stable, broad-appeal data sources can outperform sexy but high-maintenance social media scrapers.
What's Next
Now that I understand what works in the marketplace, I'm building my own Apify actor based on these insights. I'll share that journey in a future post.
Subscribe to get notified :
I'm building HAR Analyzer, a Mac app that makes the web scraping workflow you saw above 10x faster.